Big Data Camp
People working in this camp typically come from Hadoop, PIG/Hive background. They usually have implemented some domain-specific logic to process large amount of raw data. Often the logic is relatively straight-forward based on domain-specific business rules.From my personal experience, most of the people working in big data come from a computer science and distributed parallel processing system background but not from the statistical or mathematical discipline.
Deep Analysis Camp
On the other hand, people working in this camp usually come from statistical and mathematical background which the first thing being taught is how to use sampling to understand a large population's characteristic. Notice the magic of "sampling" is that the accuracy of estimating the large population depends only in the size of sample but not the actual size of the population. In their world, there is never a need to process all the data in the population in the first place. Therefore, Big Data Analytics is unnecessary under this philosophy.Typical Data Processing Pipeline
Learning from my previous projects, I observe most data processing pipeline fall into the following pattern.
In this model, data is created from the OLTP (On Line Transaction Processing) system, flowing into the BIG Data Analytics system which produced various output; including data mart/cubes for OLAP (On Line Analytic Processing), reports for the consumption of business executives, and predictive models that feedback decision support for OLTP.
Big Data + Deep Analysis
The BIG data analytics box is usually done in a batch fashion (e.g. once a day), usually we see big data processing and deep data analysis happens at different stages of this batch process.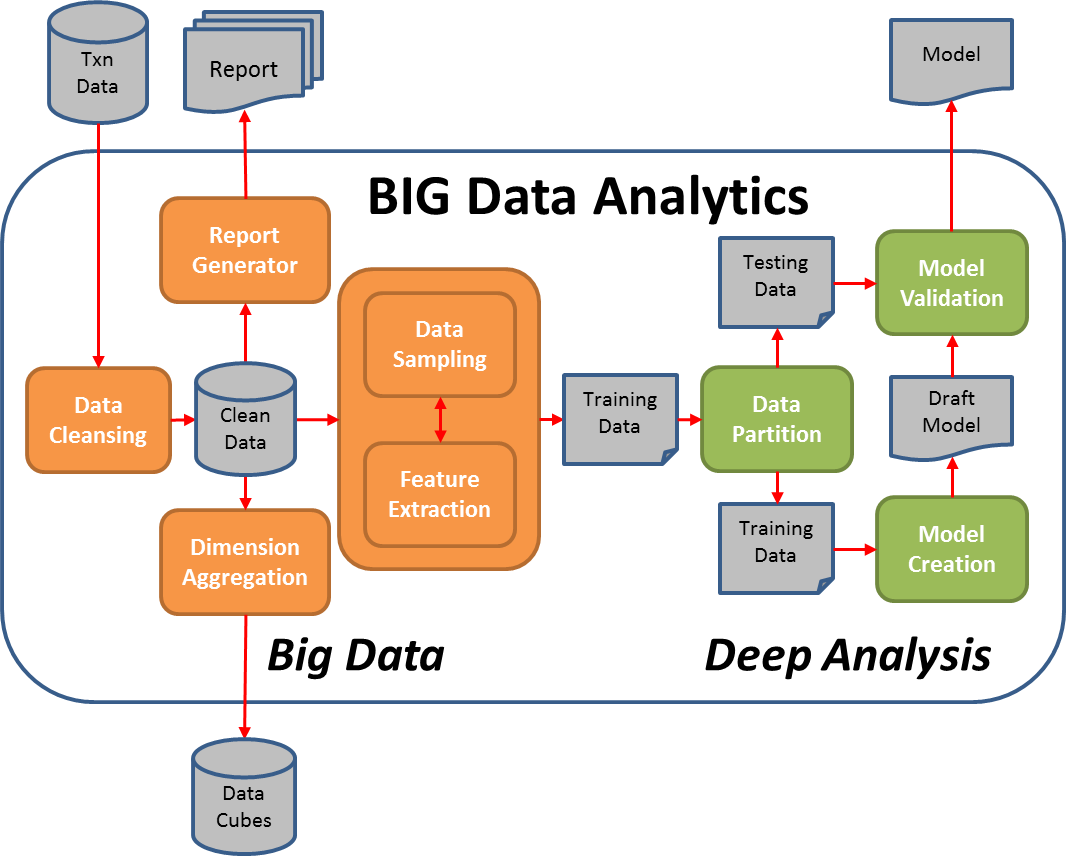
The big data processing part (colored in orange) is usually done using Hadoop/PIG/Hive technology with classical ETL logic implementation. By leveraging the Map/Reduce model that Hadoop provides, we can linearly scale up the processing by adding more machines into the Hadoop cluster. Drawing cloud computing resources (e.g. Amazon EMR) is a very common approach to perform this kind of tasks.
The deep analysis part (colored in green) is usually done in R, SPSS, SAS using a much smaller amount of carefully sampled data that fits into a single machine's capacity (usually less than couple hundred thousands data records). The deep analysis part usually involve data visualization, data preparation, model learning (e.g. Linear regression and regularization, K-nearest-neighbour/Support vector machine/Bayesian network/Neural network, Decision Tree and Ensemble methods), model evaluation. For those who are interested, please read up my earlier posts on these topics.
Implementation Architecture
There are many possible ways to implement the data pipeline described above. Here is one common implementation that works well in many projects.
In this architecture, "Flume" is used to move data from OLTP system to Hadoop File System HDFS. A workflow scheduler (typically a cron-tab entry calling a script) will periodically run to process the data using Map/Reduce. The data has two portions: a) Raw transaction data from HDFS b) Previous model hosted in some NOSQL server. Finally the "reducer" will update the previous model which will be available to the OLTP system.
For most the big data analytic projects that I got involved, the above architecture works pretty well. I believe projects requiring real-time feedback loop may see some limitation in this architecture. Real-time big data analytics is an interesting topic which I am planning to discuss in future posts.
4 comments:
Nice post, thank you.
I have a question. For the last architecture, can you please explain why MapReduce input data has two portions? Why we include model(old) every time?
Thank you to share this information about data processing services in globally. I am very happy to get this knowledge form your site because I have lot’s time invested on the internet but not reached to target information. That Data is a collection of facts, such as values or measurements.
Thanks a lot, this post helps a lot making some high-level architectural decision.
Big Data is best for financial firms to divide everything into smaller tasks, which are then distributed through many different servers.
Post a Comment