Unconstrained optimization
In an unconstraint case, the variable can be freely selected within its full range.A typical solution is to compute the gradient vector of the objective function [∂f/∂x1, ∂f/∂x2, …] and set it to [0, 0, …]. Solve this equation and output the result x1, x2 … which will give the local maximum.
In R, this can be done by a numerical analysis method.
> f <- function(x){(x[1] - 5)^2 + (x[2] - 6)^2}
> initial_x <- c(10, 11)
> x_optimal <- optim(initial_x, f, method="CG")
> x_min <- x_optimal$par
> x_min
[1] 5 6
Equality constraint optimization
Moving onto the constrained case, lets say x1, x2 … are not independent and then have to related to each other in some particular way: g1(x1, x2, …) = 0, g2(x1, x2, …) = 0.The optimization problem can be expressed as …
Maximize objective function: f(x1, x2, …)
Subjected to equality constraints:
- g1(x1, x2, …) = 0
- g2(x1, x2, …) = 0
Define a new function F as follows ...
F(x1, x2, …, λ1, λ2, …) = f(x1, x2, …) + λ1.g1(x1, x2, …) + λ2.g2(x1, x2, …) + …
Then solve for ...
[∂F/∂x1, ∂F/∂x2, …, ∂F/∂λ1, ∂F/∂λ2, …] = [0, 0, ….]
Inequality constraint optimization
In this case, the constraint is inequality. We cannot use the Lagrange multiplier technique because it requires equality constraint. There is no general solution for arbitrary inequality constraints.However, we can put some restriction in the form of constraint. In the following, we study two models where constraint is restricted to be a linear function of the variables:
w1.x1 + w2.x2 + … >= 0
Linear Programming
Linear programming is a model where both the objective function and constraint function is restricted as linear combination of variables. The Linear Programming problem can be defined as follows ...Maximize objective function: f(x1, x2) = c1.x1 + c2.x2
Subjected to inequality constraints:
- a11.x1 + a12.x2 <= b1
- a21.x1 + a22.x2 <= b2
- a31.x1 + a32.x2 <= b3
- x1 >= 0, x2 >=0
- StockA gives 5% return on average
- StockB gives 4% return on average
- StockC gives 6% return on average
To formulate this problem:
Variable: x1 = % investment in A, x2 = % in B, x3 = % in C
Maximize expected return: f(x1, x2, x3) = x1*5% + x2*4% + x3*6%
Subjected to constraints:
- 10% < x1, x2, x3 < 100%
- x1 + x2 + x3 = 1
- x3 < x1 + x2
- x1 < 2 * x2
> library(lpSolve)
> library(lpSolveAPI)
> # Set the number of vars
> model <- make.lp(0, 3)
> # Define the object function: for Minimize, use -ve
> set.objfn(model, c(-0.05, -0.04, -0.06))
> # Add the constraints
> add.constraint(model, c(1, 1, 1), "=", 1)
> add.constraint(model, c(1, 1, -1), ">", 0)
> add.constraint(model, c(1, -2, 0), "<", 0)
> # Set the upper and lower bounds
> set.bounds(model, lower=c(0.1, 0.1, 0.1), upper=c(1, 1, 1))
> # Compute the optimized model
> solve(model)
[1] 0
> # Get the value of the optimized parameters
> get.variables(model)
[1] 0.3333333 0.1666667 0.5000000
> # Get the value of the objective function
> get.objective(model)
[1] -0.05333333
> # Get the value of the constraint
> get.constraints(model)
[1] 1 0 0
Quadratic Programming
Quadratic programming is a model where both the objective function is a quadratic function (contains up to two term products) while constraint function is restricted as linear combination of variables.The Quadratic Programming problem can be defined as follows ...
Minimize quadratic objective function:
f(x1, x2) = c1.x12 + c2. x1x2 + c2.x22 - (d1. x1 + d2.x2)
Subject to constraints
- a11.x1 + a12.x2 == b1
- a21.x1 + a22.x2 == b2
- a31.x1 + a32.x2 >= b3
- a41.x1 + a42.x2 >= b4
- a51.x1 + a52.x2 >= b5
Minimize objective ½(DTx) - dTx
Subject to constraint ATx >= b
First k columns of A is equality constraint
As an illustrative example, lets continue on the portfolio investment problem. In the example, we want to find an optimal way to allocate the proportion of asset in our investment portfolio.
- StockA gives 5% return on average
- StockB gives 4% return on average
- StockC gives 6% return on average
For investment, we not only want to have a high expected return, but also a low variance. In other words, stocks with high return but also high variance is not very attractive. Therefore, maximize the expected return and minimize the variance is the typical investment strategy.
One way to minimize variance is to pick multiple stocks (in a portfolio) to diversify the investment. Diversification happens when the stock components within the portfolio moves from their average in different direction (hence the variance is reduced).
The Covariance matrix ∑ (between each pairs of stocks) is given as follows:
1%, 0.2%, 0.5%
0.2%, 0.8%, 0.6%
0.5%, 0.6%, 1.2%
In this example, we want to achieve a overall return of at least 5.2% of return while minimizing the variance of return
To formulate the problem:
Variable: x1 = % investment in A, x2 = % in B, x3 = % in C
Minimize variance: xT∑x
Subjected to constraint:
- x1 + x2 + x3 == 1
- X1*5% + x2*4% + x3*6% >= 5.2%
- 0% < x1, x2, x3 < 100%
> library(quadprog)
> mu_return_vector <- c(0.05, 0.04, 0.06)
> sigma <- matrix(c(0.01, 0.002, 0.005,
+ 0.002, 0.008, 0.006,
+ 0.005, 0.006, 0.012),
+ nrow=3, ncol=3)
> D.Matrix <- 2*sigma
> d.Vector <- rep(0, 3)
> A.Equality <- matrix(c(1,1,1), ncol=1)
> A.Matrix <- cbind(A.Equality, mu_return_vector,
diag(3))
> b.Vector <- c(1, 0.052, rep(0, 3))
> out <- solve.QP(Dmat=D.Matrix, dvec=d.Vector,
Amat=A.Matrix, bvec=b.Vector,
meq=1)
> out$solution
[1] 0.4 0.2 0.4
> out$value
[1] 0.00672
>
Integration with Predictive Analytics
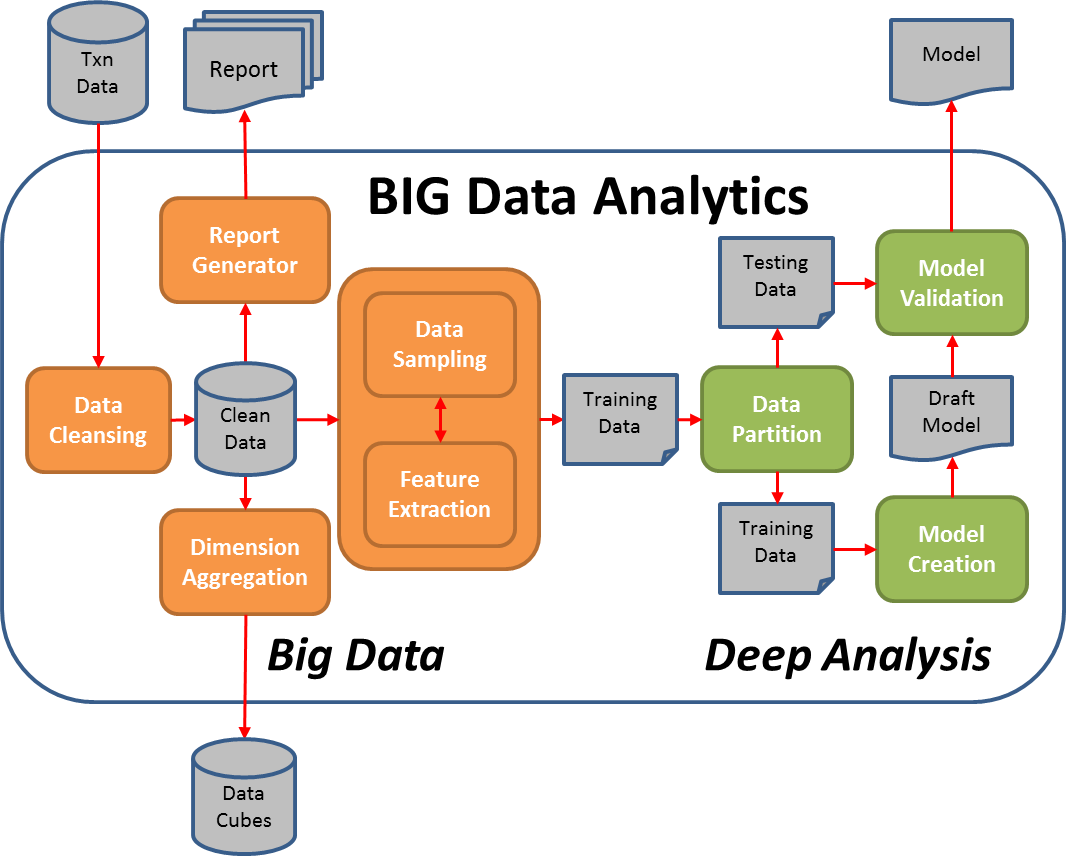
Optimization is usually integrated with predictive analytics, which is another important part of data analytics. For an overview of predictive analytics, here is my previous blog about it.The overall processing can be depicted as follows:

In this diagram, we use machine learning to train a predictive model in batch mode. Once the predictive model is available, observation data is fed into it at real time and a set of output variables is predicted. Such output variable will be fed into the optimization model as the environment parameters (e.g. return of each stock, covariance ... etc.) from which a set of optimal decision variable is recommended.